Loop engineering : ce que les boucles de Boris Cherny changent pour votre agence
Le concept de loop engineering éclaire comment les agents IA codent en boucle. Voici ce que cela signifie concrètement pour votre organisation.
Tag
9 articles
Le concept de loop engineering éclaire comment les agents IA codent en boucle. Voici ce que cela signifie concrètement pour votre organisation.
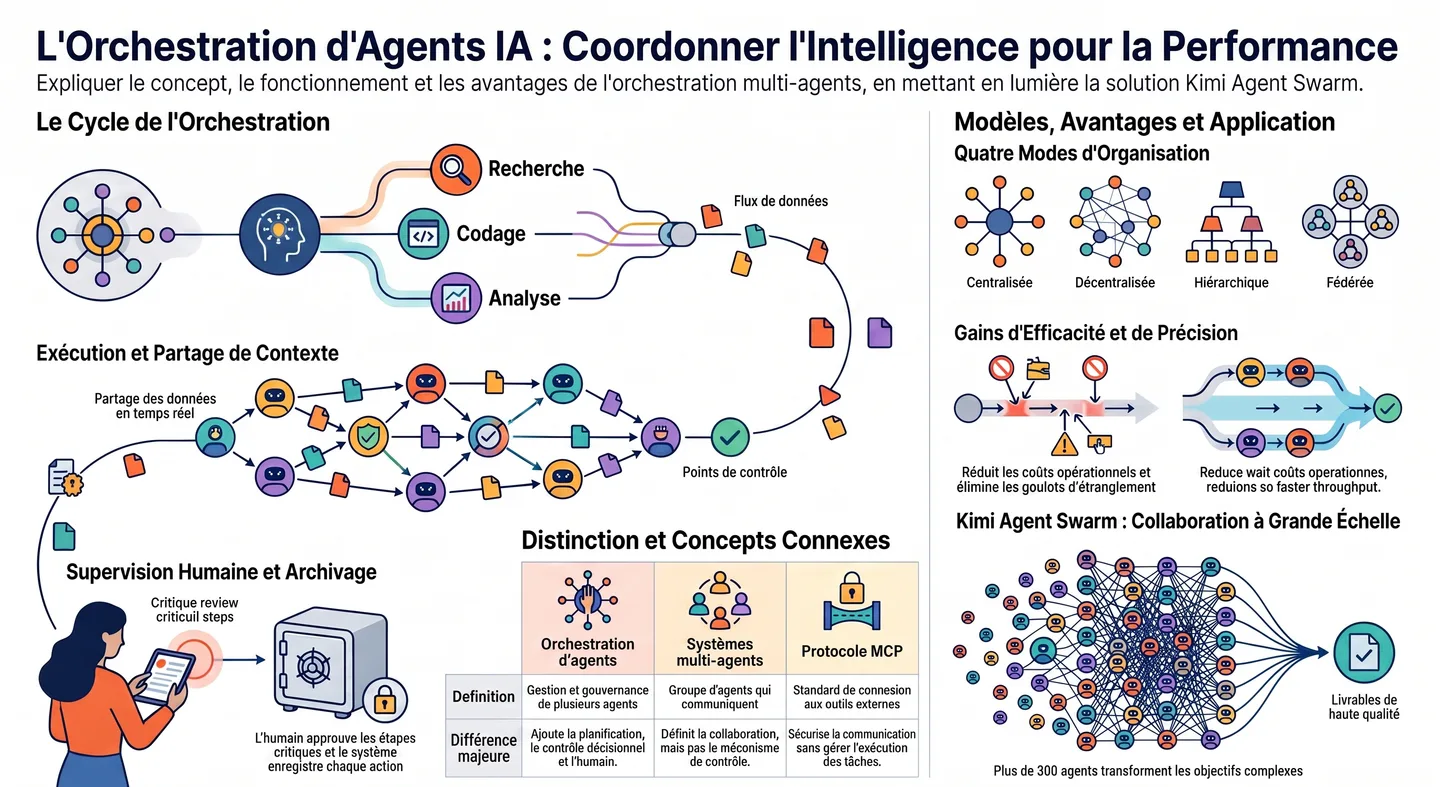
L'orchestration multi-agents promet des gains spectaculaires. Voici ce qui est solide, ce qui reste flou, et ce que ça change pour les PME.
Découvrez comment les dynamic workflows de Claude Code orchestrent des sous-agents en parallèle, avec validation croisée et relance.
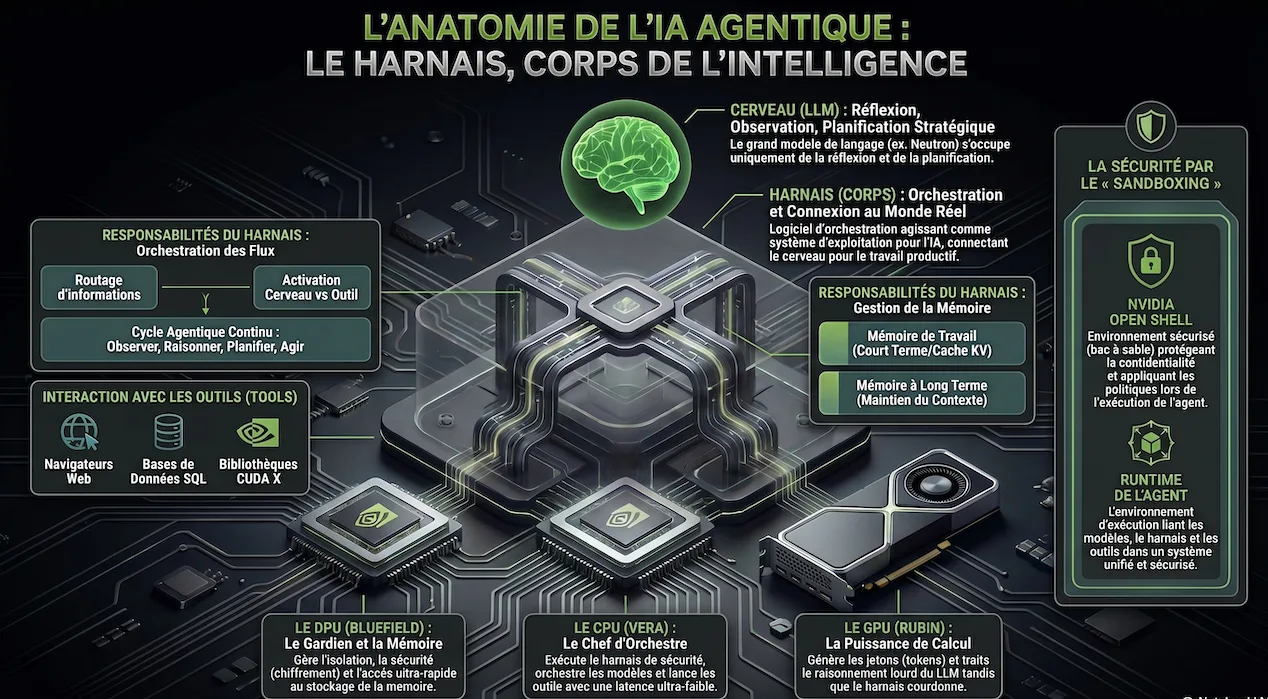
Orchestration, mémoire, outils, sécurité : le « harnais » est la couche qui rend l'IA agentique utile, gouvernable et déployable.
Définition, impacts et opportunités de l'IA agentique : nouveaux usages, nouvelle architecture cloud, nouveaux PC et enjeux de gouvernance.
Comprendre l'IA agentique, ses vrais usages en entreprise et les étapes concrètes pour automatiser sans perdre le contrôle.
Réduisez coûts et latence des LLM avec deux formats d'output (Caveman et RTK) + modèles de prompts et règles de choix.
Une étude de cas sur les risques des agents IA en production et les garde-fous à mettre en place.
Claude for Small Business automatise vos processus comptables, marketing et opérationnels en se connectant à vos outils existants.
Une veille tech utile, claire et accessible
Analyses sur l'IA, les technologies, le cloud, le marketing et l'entrepreneuriat — directement dans votre boîte mail.
Je m'abonne