MiniMax vient de teaser MiniMax M3 comme “le premier modèle open-weights” à réunir trois capacités dites frontier : coding/agents, contexte très long (jusqu’à 1M), et multimodal natif dès l’entraînement initial.
Avant d’aller plus loin, voici la traduction fidèle du message partagé.
Présentation de MiniMax M3 : le premier modèle open-weights à combiner trois capacités “frontier”
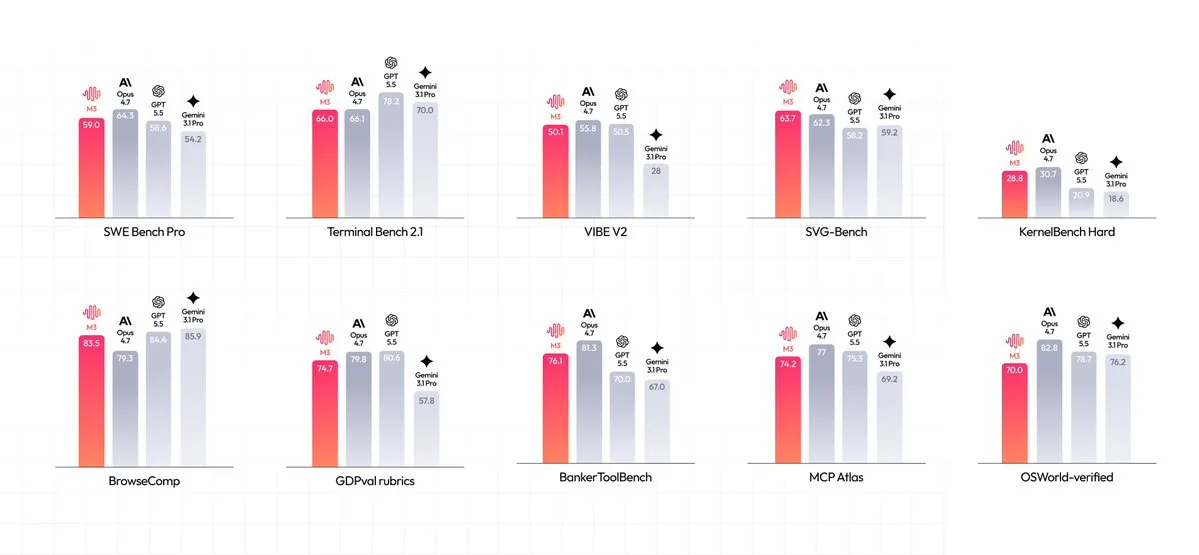
- Frontière code & agentique : 34,8 % (SWE-fficiency), 28,8 % (KernelBench Hard), 74,2 % (MCP Atlas)
- Sparse Attention MiniMax : le contexte passe à 1 million de tokens
- Multimodal natif dès l’étape zéro
API : platform.minimax.io — Poids & rapport technique dans ~10 jours
Pourquoi ce sujet est important
Pour une PME, une agence, ou une organisation, les modèles IA deviennent vraiment stratégiques quand ils cochent trois cases :
- Ils écrivent et modifient du code correctement (et peuvent agir comme des “agents” : enchaîner des tâches).
- Ils gardent le contexte (docs, historique, procédures, base de connaissances) sans tout résumer à chaque étape.
- Ils comprennent plusieurs formats (texte + images, parfois audio/vidéo), ce qui colle au réel : PDF, captures, formulaires, interfaces, etc.
Un modèle qui rassemble ces trois dimensions peut réduire le “bricolage” habituel : plusieurs outils, plusieurs modèles, des erreurs à chaque passage.
Ce qu’il faut comprendre
1) “Open-weights” : ce que ça change (et ce que ça ne change pas)
Quand un acteur annonce des poids ouverts, l’intérêt est surtout :
- Déploiement possible sur vos infrastructures ou chez un fournisseur de votre choix.
- Contrôle (conformité, localisation des données, gouvernance).
- Optimisation (fine-tuning, quantization, coûts).
Mais attention : open-weights ne veut pas forcément dire open-source complet (licence, code d’entraînement, datasets, restrictions d’usage). La valeur réelle dépendra du rapport technique et de la licence quand ils seront publiés.
2) “Coding & agentic” : au-delà du chatbot
Les métriques citées (SWE-Bench, Terminal Bench, KernelBench, MCP Atlas) signalent une ambition : un modèle capable d’exécuter des tâches techniques de bout en bout, pas seulement de “proposer du code”.
Concrètement, l’agentique devient utile quand le modèle peut :
- lire un repo, comprendre une base de code ;
- proposer et analyser des erreurs ;
- itérer jusqu’à un résultat acceptable.
Même avec de bons scores, ce n’est pas de l’autopilote : c’est un copilote plus autonome, qui exige encore de la supervision.
3) Contexte à 1M : la promesse… et ses implications
Un contexte “1M” (1 million de tokens) vise un usage très concret : mettre beaucoup plus de matière dans une même session (procédures, contrats, documentation, logs, tickets, specs).
À retenir :
- Le gain n’est pas juste “plus long”, c’est moins de friction (moins de résumés, moins de pertes de détails).
- La performance dépend souvent de la qualité de récupération d’info (RAG), de la structuration, et de la capacité du modèle à retrouver le bon passage au bon moment.
4) “Multimodal natif dès l’étape zéro”
Cette phrase est importante : certains systèmes deviennent multimodaux “par assemblage” (texte + un autre module). “Natif” suggère une intégration plus profonde dès l’entraînement.
Pour une organisation, ça peut ouvrir des possibilités concrètes :
- interpréter un PDF scanné ou une facture ;
- lire un schéma, une interface, un tableau ;
- analyser des captures d’écran de tickets ou d’erreurs.
Applications concrètes
Voici comment une PME ou une équipe com/tech peut tirer parti de ce type de modèle, si les promesses se confirment.
Support & opérations
- Copilote interne branché à votre base de connaissances : procédures, FAQ, documentation, historiques d’incidents.
- Analyse de captures d’écran (tickets), extraction d’info depuis des documents.
Développement & produit
- Assistance plus robuste sur des tâches “réelles” : refactor, migrations, tests, scripts, CI/CD.
- Agent qui aide à reproduire un bug à partir d’un log + capture + contexte.
Communication & marketing (multimodal)
- Comprendre des assets visuels (maquettes, pages web, screenshots) pour proposer des variantes de contenu.
- Contrôles de cohérence : “est-ce que cette landing page respecte les éléments clés de la charte ?”
Points de vigilance
- Benchmarks ≠ réalité terrain : ils donnent un signal, mais votre cas d’usage réel fait la différence.
- Coûts & latence : le “contexte 1M” peut coûter cher si vous l’alimentez sans stratégie (il faut filtrer, structurer, récupérer intelligemment).
- Gouvernance : qui a le droit d’envoyer quoi au modèle ? Comment tracer les réponses ? Comment éviter les fuites ?
- Licence et conditions d’usage : à vérifier dès publication des poids et du rapport.
Ce que les organisations devraient faire maintenant
- Lister 5 cas d’usage où vous perdez du temps à cause du contexte (docs dispersées, tickets, historiques, procédures).
- Préparer une base documentaire propre (noms, versions, sources, propriétaires).
- Définir un “kit de test” : 20 questions/tâches réelles pour évaluer un modèle (qualité, sécurité, coût).
- Mettre en place une stratégie RAG (recherche + citations internes) avant de rêver au “1M tokens partout”.
Si vous suivez déjà les tendances IA côté organisation, ce sujet s’inscrit bien dans la continuité de ce qu’on voit en 2026 : l’enjeu n’est plus seulement le modèle, mais son intégration, ses données et sa gouvernance.
Conclusion
MiniMax M3 se positionne sur un trio très stratégique : agentique (code), contexte extrême (1M), multimodal natif. Si les poids et le rapport technique confirment la promesse — et si la licence est exploitable — on pourrait avoir une option open-weights intéressante pour des organisations qui veulent plus de contrôle sur leurs déploiements IA.
Vous souhaitez appliquer ces idées à votre organisation ? FD Stratégies peut vous accompagner dans la création de solutions numériques, l’automatisation de vos processus et la structuration de votre présence en ligne.